
WARNING: This is a Bayesian perspective on a frequentist procedure. Consequently, hard-core frequentists may protest and argue that, for the goals that they pursue, everything makes perfect sense. Bayesians will remain befuddled. Also, I’d like to thank Richard Morey for insightful, critical, and constructive comments.
In an unlikely alliance, Deborah Mayo and Richard Morey (henceforth: M&M) recently produced an interesting and highly topical preprint “A poor prognosis for the diagnostic screening critique of statistical tests”. While reading it, I stumbled upon the following remarkable statement-of-fact (see also Casella & Berger, 1987):
“Let our goal be to test the hypotheses:
against
The test is the same if we’re testing
against
.”
Wait, what? This equivalence may be defensible from a frequentist point of view (e.g., if you reject 
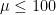

As a demonstration, below I will discuss three concrete data scenarios.
To prevent confusion, the hypothesis “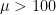
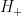

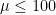

Scenario I: $m=0$
In this hypothetical scenario, the sample mean 

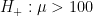
A different interpretation is that $H_-$ ought to be punished for mispredicting the effect to be negative, just as 
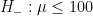

The distinction between “maximum possible support” and “no support whatsoever” is dramatic and becomes arbitrarily large as sample size increases.
Scenario II: 
Suppose the data are strongly consistent with
Consider three friends –Moe, Larry, and Curly– who each predicted the outcome of the 2018 armwrestling match between Devon “No Limits” Larratt and Denis “The Hulk” Cyplenkov. Moe predicted that Devon and Denis would be evenly matched; Larry predicted that Devon would embarrass Denis by bleeding him dry, and Curly predicted that Denis would steamroll Devon with his superior strength. As it turned out, Cyplenkov swept Devon 6-0. It is clear that Curly predicted the outcome best; Moe was wrong, but, crucially, he was much less wrong than Larry, who predicted that the result would be the other way around.
Scenario III: 
Finally, consider the possibility that the sample mean $m$ is much lower than zero, that is, in the direction opposite of that specified by
In sum, for none of the scenarios considered above does the support for the point null hypothesis $H_0$ equal the support for the directional hypothesis $H_-$. Frequentists may counter than they are not interested in concepts such as support, evidence, logic, or common sense. Perhaps there are more compelling counterarguments to the demonstrations above, but I have yet to come across them.
The Fundamental Problem of the Frequentist One-Sided Test
The core problem of the frequentist one-sided test, at least when viewed as test of 
In light of this new knowledge, how should the hypotheses be adjusted? In my opinion, the skeptic’s position should remain unaltered: she still believes that any effects in the sample are spurious, and there is no meaningful relation between pupil size and IQ. After all, the neurobiological theory on pupil size assumes that a relation exists, and this is the very assumption that the skeptic wants to put to the test. On the other hand, the new knowledge should affect the position of the proponent, as it allows her to formulate more precise predictions.
In other words, the knowledge that the effect –should it exist!– is positive rather than negative, ought to affect the specification of
To conclude, from a Bayesian perspective the frequentist treatment of the one-sided test seems to violate a series of fundamental desiderata for statistical support. Frequentists may argue, as noted above, that “support”, “evidence”, and “comparison of hypotheses” is not what they care about. Still, it is important for practitioners to realize what they are getting into when they decide to put on the frequentist yoke.
The Bayesian View
The Bayesian analysis of the one-sided test is very different from the frequentist one-sided test. First of all, let’s establish that it is perfectly possible (and often recommended) in the Bayesian framework to compare
However, it is also possible to retain the skeptic’s null hypothesis and compare its predictions against those from an order-restricted alternative hypothesis,
So we may entertain the following hypotheses, all of which make different predictions:
- The skeptic’s null hypothesis,
, which stipulates the effect to be absent;
- The proponent’s alternative hypothesis,
, which stipulates the effect to be present but leaves the direction unspecified;
- The proponent’s positive-only hypothesis
, which stipulates the effect to be present and positive;
- The proponent’s negative-only hypothesis
, which stipulates the effect to be present and negative.
Depending on the nature of the scientific investigation, the comparison between any two hypotheses may be of interest. A Bayesian directional test compares
In contrast to the frequentist approach, the Bayesian treatment of the one-sided test is relatively flexible and does not necessitate a qualitative change to a directional question. As we have seen from the scenarios above, the one-sided test and the directional test lead to logically incompatible measures of support, quite independent of the choice of prior. If you know that your method yields a fundamentally different results from a Bayesian analysis, irrespective of the prior distributions, you should start to worry.
Only recently I found that the one-sided Bayesian test is discussed in Jeffreys (1961, p. 283):
“But where there is a predicted standard error the type of disturbance chiefly to be considered is one that will make the actual one larger, and verification is desirable before the predicted value is accepted. Hence we also consider the case where
is restricted to be non-negative.”
Jeffreys then continues to discuss the three scenarios discussed at the start of this post.
Summary
Chapter 2 from Alice in Wonderland is called “The pool of tears”. At some point in the chapter, Alice cries out “curiouser and curiouser!” Perhaps it should not be surprising that frequentist one-sided tests do not withstand a critical Bayesian examination, given that the two-sided version has already succumbed (e.g., Jeffreys, 1961). It is surprising, though, that central concepts such as the one-sided test can be seen to violate common-sense desiderata of statistical support.
References
Casella, G. and Berger, R. L. (1987). Reconciling Bayesian and Frequentist evidence in the one-sided testing problem. Journal of the American Statistical Association, 82, 106-111.
Marsman, M., & Wagenmakers, E.-J. (2017). Three insights from a Bayesian interpretation of the one-sided P value. Educational and Psychological Measurement, 77, 529-539.
Mayo, D., & Morey, R. D. (2018). A poor prognosis for the diagnostic screening critique of statistical tests. PsyArXiv preprint: https://osf.io/ps38b/.
Morey, R. D., & Wagenmakers, E.-J. (2014). Simple relation between Bayesian order-restricted and point-null hypothesis tests. Statistics and Probability Letters, 92, 121-124.
About The Author

Eric-Jan Wagenmakers
Eric-Jan (EJ) Wagenmakers is professor at the Psychological Methods Group at the University of Amsterdam.


