Preprint: Same same but different? A closer look at the Sequential Probability Ratio Test and the Sequential Bayes Factor Test
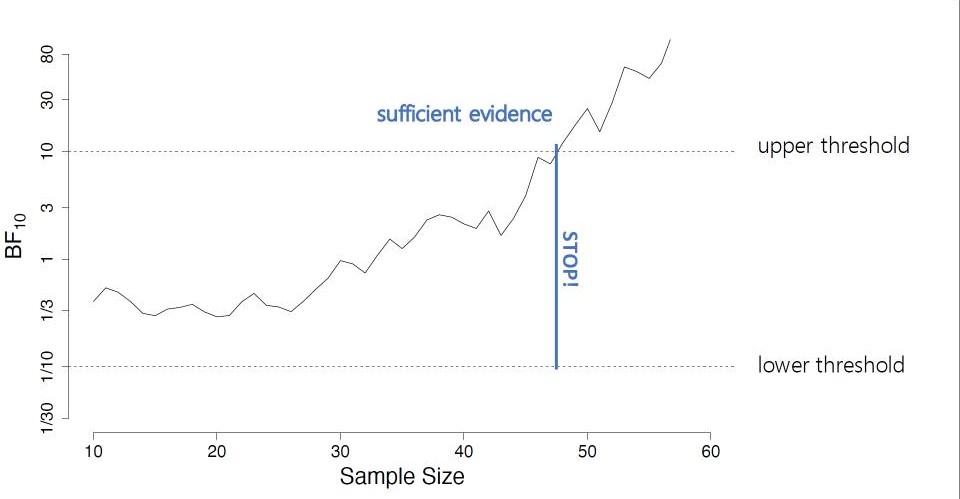
This post is an extended synopsis of Stefan, A. M., Schönbrodt, F. D, Evans, N. J., & Wagenmakers, E.-J. (2020). Efficiency in Sequential Testing: Comparing the Sequential Probability Ratio Test and the Sequential Bay Abstract Analyzing data from human research participants is at the core of psychological science. However, data collection comes at a price: It requires time, monetary resources,…
read more