
The Misconception
Posterior Bayes factors are a good idea: they provide a measure of evidence but are relatively unaffected by the shape of the prior distribution.
The Correction
Posterior Bayes factors use the data twice, effectively biasing the outcome in favor of the more complex model.
The Explanation
The standard Bayes factor is the ratio of predictive performance between two rival models. For each model 
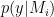
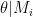
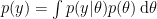
The wish to produce predictions without opening oneself up to the unwanted impact of the prior distribution has spawned an alternative to the standard Bayes factor, one in which predictions are obtained not from the prior distribution, but from the posterior distribution. This “postdictive” performance is then given by averaging the likelihood over the posterior, yielding 


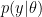
As the rebuttal shows, Aitkin was not impressed, neither by the general argument nor by the concrete examples. Here we provide another example of posterior Bayes factors in action. Consider a binomial problem where 


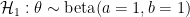
Consider first the general expression for the Bayes factor in favor of 
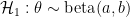
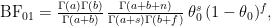
where 

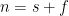
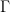

We then simplify this equation by inserting the following information: (1) 
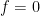

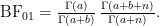
If we assume that 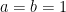


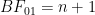
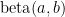
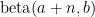
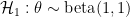


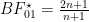
Table 1 below shows the results for various numbers of confirmatory instances 



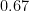
| No. confirmations |
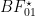 |
| 1 | 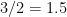 |
| 2 | 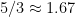 |
| 3 |  |
| 4 |  |
| 5 |  |
 |
2 |
Table 1. As the number of confirmatory instances
The result from Table 1 can be easily confirmed using the SumStat module in JASP (Ly et al., 2018 

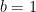
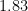
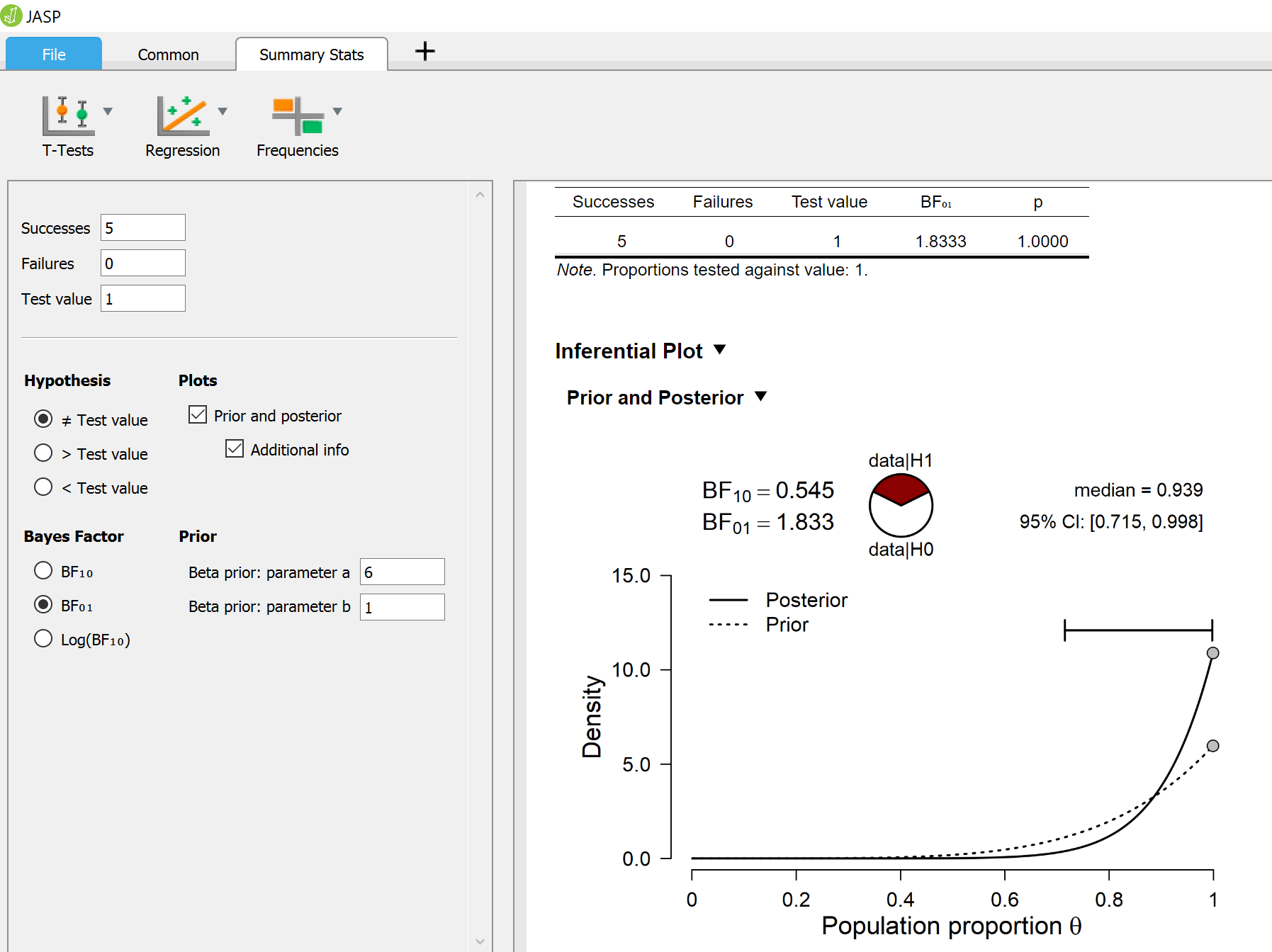
Concluding Comments
As demonstrated above, posterior Bayes factors violate the fundamental inductive pattern. No matter how many apples one sees that grow from apple trees, no matter how many even integers greater than two are inspected that turn out to be the sum of two prime numbers, our confidence in these general laws would be bounded, and would forever remain caught in the evidential region that Jeffreys (1961, appendix B) called “not worth more than a bare mention”. This is preposterous.
The reason for such problematic behavior is the same as for LOO (Gronau et al., in press a, b): when two models are provided advance access to the data they are supposed to predict, this benefits the complex model much more than the simple model. If the data are consistent with the simple model, the complex model will abuse the advance access to the data to tune its parameters so that it effectively mimics the simple model; the comparison is then not between a complex model and a simple model, but between two simple and highly similar models — such a comparison cannot produce a diagnostic result.
In sum, we believe that models, hypotheses, and theories need to be assessed by the predictions that they make. Predictions, as the word suggests, need to come from the prior, not from the posterior. The famous Danish maxim tells us that “prediction is hard, particularly about the future”; the difficulty is real, but this does not license us to abandon the enterprise and start assessing our theories by postdiction instead.
Footnotes
1 For a general beta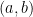

References
Aitkin, M. (1991). Posterior Bayes factors. Journal of the Royal Statistical Society. Series B (Methodological), 53, 111-142.
Gronau, Q. F., & Wagenmakers, E.-J. (in press a). Limitations of Bayesian leave-one-out cross-validation for model selection. Computational Brain & Behavior. Preprint.
Gronau, Q. F., & Wagenmakers, E.-J. (in press b). Rejoinder: More limitations of Bayesian leave-one-out cross-validation. Computational Brain & Behavior. Preprint.
Jeffreys, H. (1961). Theory of probability (3rd ed.). Oxford: Oxford University Press.
Ly, A., Raj, A., Etz, A., Marsman, M., Gronau, Q. F., & Wagenmakers, E.-J. (2018). Bayesian reanalyses from summary statistics: A guide for academic consumers. Advances in Methods and Practices in Psychological Science, 3, 367-374. Preprint; open access available through the journal website.
Polya, G. (1954). Mathematics and plausible reasoning: Vol. II. Patterns of plausible inference. Princeton, NJ: Princeton University Press.
Wendel, J. (1948). Note on the gamma function. The American Mathematical Monthly, 55, 563-564.
Appendix
Let

The limit of the posterior Bayes factor as
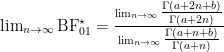
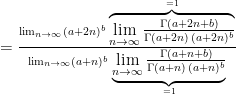
![= \lim_{n \to \infty}\left[\frac{a+2n}{a+n}\right]^b](https://s0.wp.com/latex.php?latex=%3D+%5Clim_%7Bn+%5Cto+%5Cinfty%7D%5Cleft%5B%5Cfrac%7Ba%2B2n%7D%7Ba%2Bn%7D%5Cright%5D%5Eb&bg=ffffff&fg=000&s=0&c=20201002)
![= \left[ \lim_{n \to \infty}\frac{a+2n}{a+n}\right]^b](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5B+%5Clim_%7Bn+%5Cto+%5Cinfty%7D%5Cfrac%7Ba%2B2n%7D%7Ba%2Bn%7D%5Cright%5D%5Eb+&bg=ffffff&fg=000&s=0&c=20201002)

where we used the well-known result that 


About The Authors

Eric-Jan Wagenmakers
Eric-Jan (EJ) Wagenmakers is professor at the Psychological Methods Group at the University of Amsterdam.

Quentin Gronau
Quentin is a PhD candidate at the Psychological Methods Group of the University of Amsterdam.


