
This post summarizes the content of an article that is in press for PLOS ONE. The preprint is available on PsyArXiv.
Efficient medical progress requires that we know when a treatment effect is absent. We considered all 207 Original Articles published in the 2015 volume of the New England Journal of Medicine and found that 45 (21.7%) reported a null result for at least one of the primary outcome measures. Unfortunately, standard statistical analyses are unable to quantify the degree to which these null results actually support the null hypothesis. Such quantification is possible, however, by conducting a Bayesian hypothesis test. Here we reanalyzed a subset of 43 null results from 36 articles using a default Bayesian test for contingency tables. This Bayesian reanalysis revealed that, on average, the reported null results provided strong evidence for the absence of an effect. However, the degree of this evidence is variable and cannot be reliably predicted from the p-value (see Figure 1). For null results, sample size is a better (albeit imperfect) predictor for the strength of evidence in favor of the null hypothesis (see Figure 2). Together, our findings suggest that (a) the reported null results generally correspond to strong evidence in favor of the null hypothesis; (b) a Bayesian hypothesis test can provide additional information to assist the interpretation of null results.
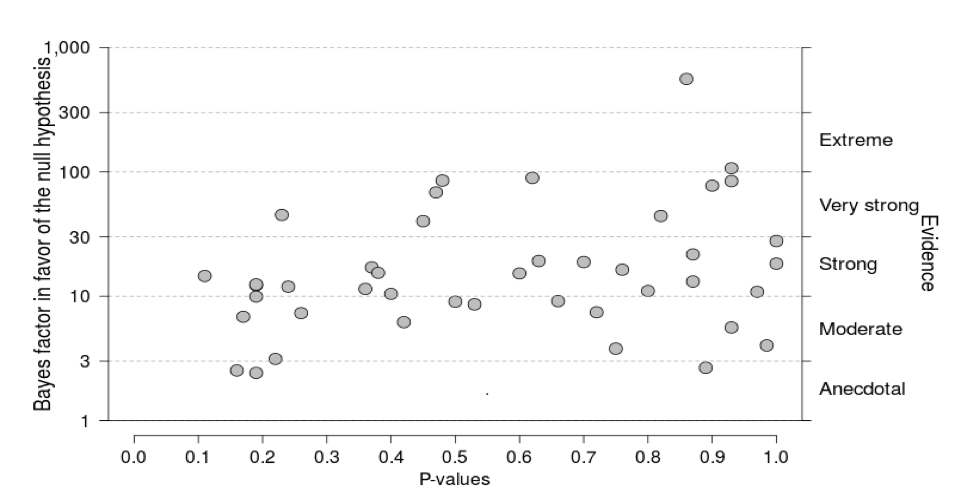
Fig 1. Relation between p-values and Bayes Factors. P-values and Bayes factors in favor of the null hypothesis for 43 null results from the 2015 volume of NEJM. All Bayes factors indicate support in favor of the null hypothesis, and most Bayes factors do so in a compelling fashion. At the same time, the support in favor of the null hypothesis is highly variable. The p-value only explains 8.39% of the variance in the log Bayes factors (r=0.29).
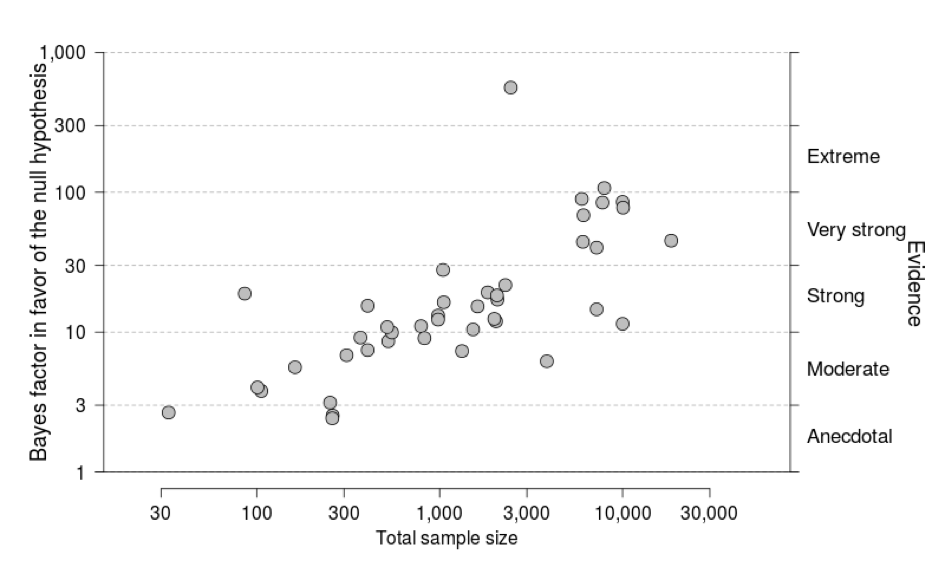
Fig 2. Relation between sample size and Bayes Factors. Among the 43 null results from the 2015 volume of NEJM, large samples are more likely to yield compelling evidence in favor of the null hypothesis than small samples (r=0.72).
Like this post?
Subscribe to the JASP newsletter to receive regular updates about JASP including all its Bayesian analyses! You can unsubscribe at any time.References
Hoekstra, R., Monden, R., van Ravenzwaaij, D., & Wagenmakers, E.-J. (in press). Bayesian reanalysis of null results reported in the New England Journal of Medicine: Strong yet variable evidence for the absence of treatment effects. PLOS ONE.
About The Author

Rink Hoekstra
Rick Hoekstra is assistant professor at the University of Groningen in The Netherlands. His research is focused on the use and misuse of inferential statistical methods.


