Coherence Revisited
The previous post gave a demonstration of Bayes factor coherence. Specifically, the post considered a test for a binomial parameter 

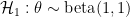


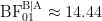

The Bayes Factor Coherence Plot
Bayes factor detractors may argue that batches A and B were cherry-picked, and that this particular sequence of successes and failures is relatively unlikely under the models considered. This objection is both correct and irrelevant. The pattern of coherence is entirely general. To appreciate this, we first write the Bayes factor on a batch-by-batch basis, using the law of conditional probability:

Thus, the coherence of the Bayes factor does not depend on how the batches are constructed. It is insightful to take the logarithm of the Bayes factor and obtain:
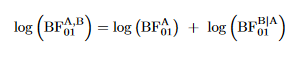
The log transformation accomplishes the following:
- Multiplication is changed to addition, which is a simpler operation.
- Evidence is symmetrized. For regular Bayes factors, positive evidence ranges from 1 to infinity, whereas negative evidence is compressed to the interval from 0 to 1. For instance,
is of the same evidential strength as
, only differing in direction. This is brought out more clearly when the logarithm is used, as
and
- Evidence in favor of
) yields a positive number (i.e.,
) whereas evidence in favor of
(i.e.,
) yields a negative number (i.e.,
), with
indicating evidential irrelevance or evidential neutrality.
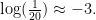
Applying the log transform to our example data yields the result visualized in the figure below, which may be termed a “Bayes factor coherence plot”:
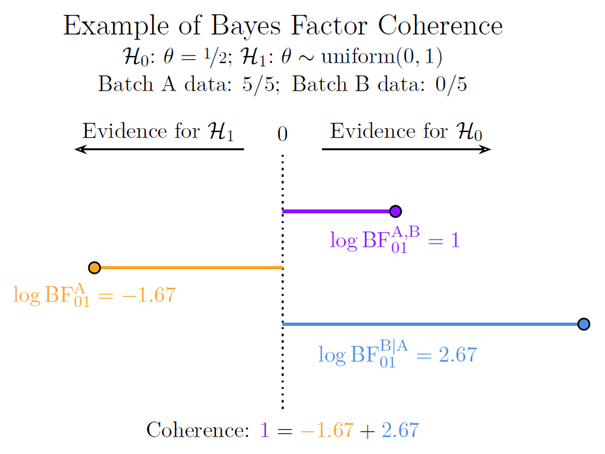
Let’s unpack. The purple line on top indicates the logarithm of the Bayes factor for the complete data set, that is, 

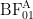
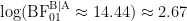
A Bayesian Boomerang
Expressed in the usual way, coherence takes a multiplicative form: 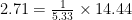
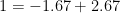
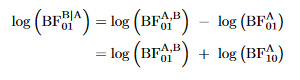
Whenever 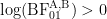
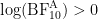
We may entertain a different division of the data into batches A and B, or we may specify more than two batches – we may even specify each batch to contain a single observation. However the data are subdivided, the end result is always coherent in the sense displayed in the coherence plot: the log Bayes factors for the individual batches are simply added and always yield a result identical to the log Bayes factor for the complete data set.
The main point of this series of blog posts is not to argue that Bayes factors are coherent (even though they are); it is also not to suggest that such coherence is elegant (even though I believe it is); rather, the main point is to demonstrate that the coherence comes about because the Bayes factors are sensitive to the prior distribution. This is a perfect, Goldilocks kind of sensitivity: not too little, not too much, but exactly the right amount in order to ensure that the method does not fall prey to internal contradictions.


