
We thank Alexander Ly for constructive comments on an earlier draft of this post.
Bayes’ rule tells us how to learn from experience, that is, by updating our knowledge about the world using relative predictive performance: hypotheses that predicted the data relatively well receive a boost in credibility, whereas hypotheses that predicted the data relatively poorly suffer a decline (e.g., Wagenmakers et al., 2016). This predictive updating principle holds for propositions, hypotheses, models, and parameters: every time, our uncertainty is updated using the same mathematical operation. Take for instance the learning process involving just two models, 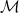

This equation shows that the change from prior odds to posterior odds is brought about by a predictive updating factor that, for model selection, is widely known as the Bayes factor (e.g., Etz & Wagenmakers, 2017) So we have prior knowledge, we use it to make predictions, and the adequacy of these predictions drives an optimal, cyclical learning process that is visualized in the figure below:
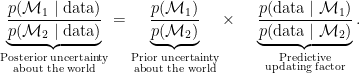
Intuitive and elegant, the Bayesian formalism does not seem to leave much room for grotesque misinterpretation concerning, for instance, hypothetical data sets with imaginary results that depend on intentions accessible only to the experimenter at the time of data collection (e.g., Berger & Wolpert, 1988). We present the algorithm again, in words:

The most common misinterpretation is to confuse the predictive updating factor, that is, the evidence, with the end result — the present uncertainty. If
Example 1: The Data Provide No Evidence At All
Billy Bob, a history undergrad, needs to write a report on whether the 1969 Apollo 11 moon landing was real news (
Example 2: Extrasensory Perception
In 2011, Daryl Bem published an infamous article in which he argued that people have precognition, a form of extrasensory perception that allows them to predict the future (Bem, 2011). In Bem’s first experiment, “Precognitive Detection of Erotic Stimuli”, each of 100 Cornell undergraduates were asked to guess, repeatedly, which of two curtains on the computer screen was hiding a picture. As the location of the picture was determined randomly, participants could perform reliably better than chance (50%) only if they had precognition. The results were as follows:
“Across all 100 sessions, participants correctly identified the future position of the erotic pictures significantly more frequently than the 50% hit rate expected by chance: 53.1%, t(99) = 2.51, p = .01, d = 0.25.” (Bem, 2011, p. 409)
We can analyze these data in JASP (jasp-stats.org) using the Summary Stats module (Ly et al., in press). We select the “one sample t-test”, add “2.51” for the t-value and “100” for the group size. The result is a Bayes factor of about 2 in favor of the precognition hypothesis over the null hypothesis, a level of evidence that is relatively weak.
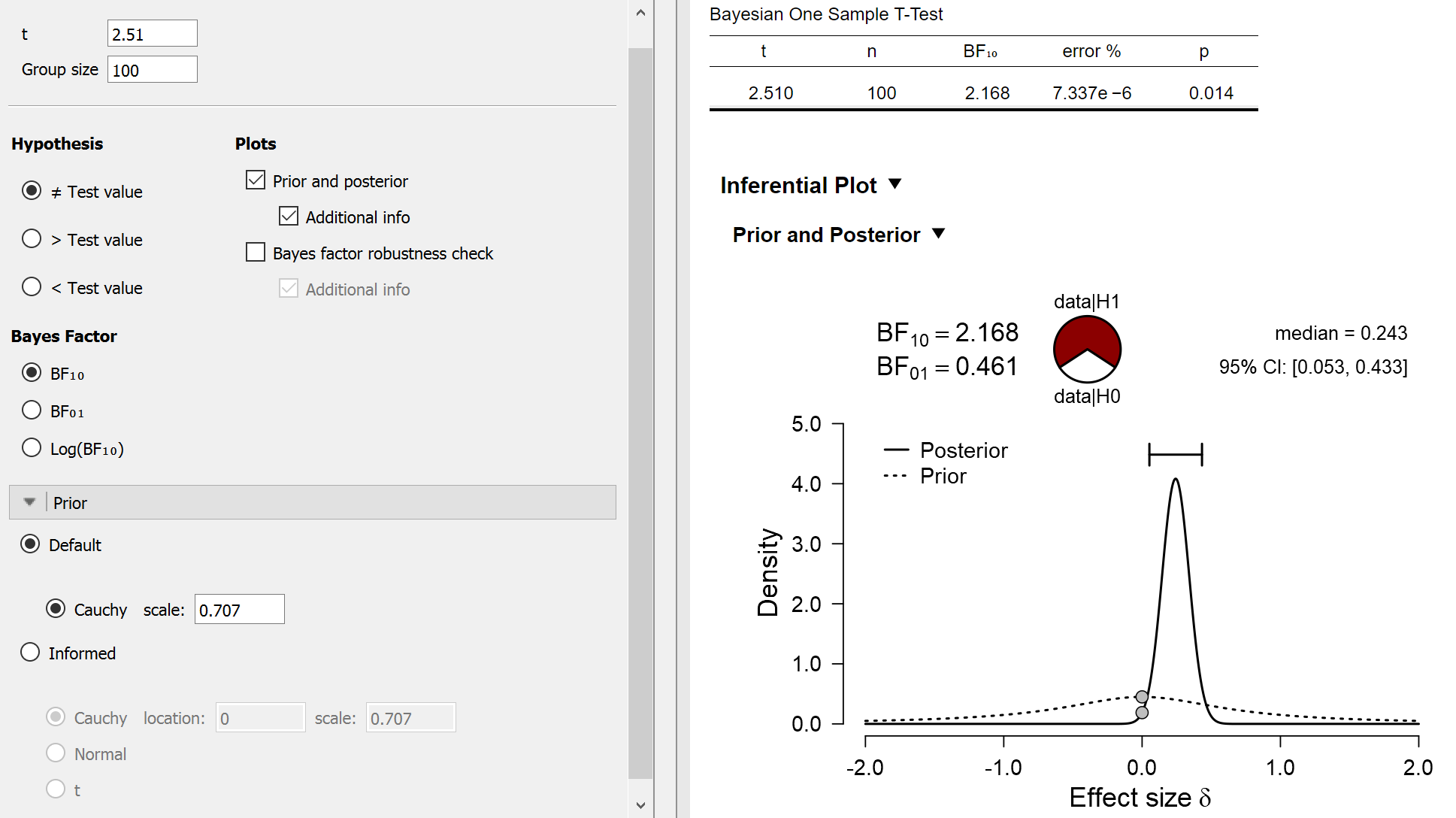
However, we can try different analyses by changing our expectations for effect size under the precognition hypothesis. For instance, we may include an order-restriction and only predict positive effects, that is, precognition only acts to increase, not decrease, detection rates. We might also use a more informed distribution (Gronau et al., 2018); for illustrative purposes we will use the “Oosterwijk prior”, a generic prior for small to medium effects. The Oosterwijk prior is a t-distribution with location 0.350, scale 0.102, and 3 degrees of freedom. The results of the informed analysis are shown below:
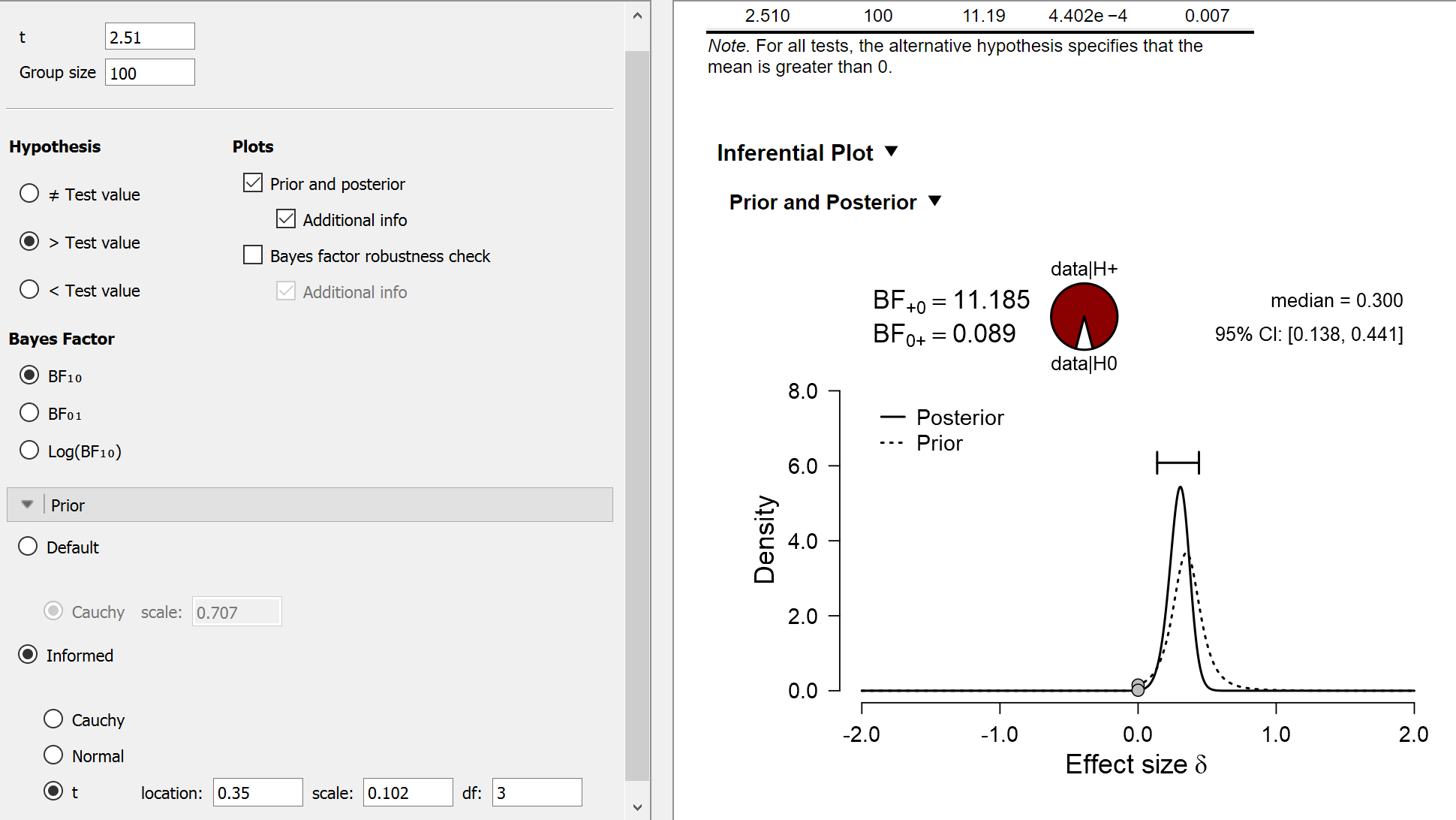
The new analysis shows that the Bayes factor equals about 11. Now there are some serious issues with these data and with this particular analysis, but for the moment we will let that slide and just consider the Bayes factor of 11 in favor of precognition. Does this result (taken at face value) mean that the precognition hypothesis is now 11 times more plausible than the skeptics’ null hypothesis? Of course not: the precognition hypothesis is highly unlikely a priori, and the Bayes factor only looks at the change in beliefs that is brought about by the data. Thus, even though your change in belief brought about by the data might be considerable, your beliefs about the world may not have changed much in absolute terms. A very, very small number multiplied with a very large number still yields a very small number, see the first equation above. The next example illustrates this on a classic textbook example.
Example 3: Drunk Driving and the Base Rate Fallacy
The prototypical demonstration of the fact that evidence does not equal posterior belief is given by the base rate fallacy: a test with fantastic operating characteristics may actually provide a deeply misleading impression of the final belief state. The basic problem features in every textbook on probability, and it is usually concluded that the Bayesian solution is too complicated for people to wrap their heads around. Indeed, the Bayesian solution is complicated when it is presented as a single step. Break it down into its component steps, and the process becomes much simpler.
Let’s consider the same problem as is mentioned on the Wikipedia page for the base rate fallacy:
“A group of police officers have breathalyzers displaying false drunkenness in 5% of the cases in which the driver is sober. However, the breathalyzers never fail to detect a truly drunk person. One in a thousand drivers is driving drunk. Suppose the police officers then stop a driver at random, and force the driver to take a breathalyzer test. It indicates that the driver is drunk. We assume you don’t know anything else about him or her. How high is the probability he or she really is drunk? Many would answer as high as 95%, but the correct probability is about 2%.”
In the first step of our Bayesian analysis of this problem, we take stock of our prior information: “one in a thousand drivers is driving drunk”. This means that p(drunk) = 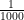
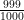

In the second step we consider the evidence that is provided by the data. We know that the breathalyzer test is positive. The probability of this happening for drunk drivers is 1, and for sober drivers it is .05. The Bayes factor in favor of the driver being drunk rather than sober is therefore: p(test positive | drunk) / p(test positive | sober) = 1/.05 = 20.
In the third step we combine our prior information (i.e., odds of 999 in favor of the driver being sober) with the evidence from the test (i.e., a Bayes factor of 20 in favor of the driver being drunk) in order to arrive at the posterior odds, that is, p(drunk | test positive) / p(sober | test positive). The odds for the driver being sober were 999 prior to the test result; the test result, however, is positive and this requires a downward adjustment by a factor of 20, so that the posterior odds for the driver being sober have been reduced to 999/20 = 49.95. This step is intuitive but can be formalized by rewriting our first equation as follows:
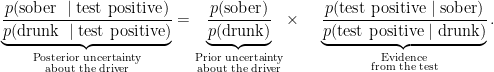
In the final step, we transform the posterior odds of 49.95 for the driver being sober to a posterior probability: p(sober | test positive) = 49.95 / (49.95+1) 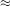
The standard Bayesian solution to the base rate fallacy involves the law of total probability in order to compute p(positive test) as p(positive test | drunk)p(drunk) + p(positive test | sober)p(sober) and then use this as the denominator in a fraction with p(positive test | drunk)p(drunk) as the numerator. The end-result is obtained in one step, but requires three simultaneous operations: multiplication, addition, and division. In contrast, the odds form of Bayes’ rule is intuitive and immediately clarifies the importance of the prior odds and the separate role of evidence.1
Example 4: Popper on Corroboration
Karl Popper was notoriously grumpy (and deeply mistaken, in our opinion2) about all things Bayesian. One example is relevant for our current discussion. Here Popper (1959) wishes to demonstrate that degree of corroboration cannot be identified with a probability3:
“Consider the next throw with a homogeneous die. Let
be the statement ‘six will turn up’; let
be its negation, that is to say, let
; and let
be the information ‘an even number will turn up’.
We have the following absolute probabilities:
Moreover, we have the following relative probabilities:
We see that
[…] expresses a fact we have established by our example: thatto
. We also see that
to
. Nevertheless, we have p(x|z) < p(y|z).
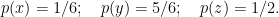

Popper’s demonstration is yet another example of the fact that evidence does not equal posterior belief. We started with prior odds p(y)/p(x) = 5, favoring 
To conclude, in Popper’s example the statement
We hope that these four examples helped clarify a misinterpretation of Bayes’ rule that is common among newcomers to Bayesian inference: change in belief does not equal posterior belief.
Footnotes
1 For a more extensive treatment see one of John Kruschke’s blog posts.
2 An opinion we are honored to share with Harold Jeffreys.
3 In the fragment below we have modernized Popper’s notation for conditional probability.
References
Bem, D. J. (2011). Feeling the future: Experimental evidence for anomalous retroactive influences on cognition and affect. Journal of Personality and Social Psychology, 100, 407-425.
Berger, J. O., & Wolpert, R. L. (1988). The Likelihood Principle (2nd ed.). Hayward (CA): Institute of Mathematical Statistics.
Gronau, Q. F., Ly, A., & Wagenmakers, E.-J. (2018). Informed Bayesian t-tests. Manuscript submitted for publication. Available at https://arxiv.org/abs/1704.02479.
Ly, A., Raj, A., Marsman, M., Etz, A., & Wagenmakers, E.-J. (2018). Bayesian Reanalyses from summary statistics: A guide for academic consumers. Advances in Methods and Practices in Psychological Science, 3, 367-374. Open Access.
Popper, K. R. (1959). The Logic of Scientific Discovery. New York: Harper Torchbooks.
Wagenmakers, E.-J., Morey, R. D., & Lee, M. D. (2016). Bayesian benefits for the pragmatic researcher. Current Directions in Psychological Science, 25, 169-176.
About The Authors

Eric-Jan Wagenmakers
Eric-Jan (EJ) Wagenmakers is professor at the Psychological Methods Group at the University of Amsterdam.

Alexander Etz
Alexander is a PhD student in the department of cognitive sciences at the University of California, Irvine.

Quentin Gronau
Quentin is a PhD candidate at the Psychological Methods Group of the University of Amsterdam.

Fabian Dablander
Fabian is a PhD candidate at the Psychological Methods Group of the University of Amsterdam. You can find him on Twitter @fdabl.


