
Background: the 2018 article “Redefine Statistical Significance” suggested that it is prudent to treat p-values just below .05 with a grain of salt, as such p-values provide only weak evidence against the null. By threatening the status quo, this modest proposal ruffled some feathers and elicited a number of counterarguments. As discussed in this series of posts, none of these counterarguments pass muster. Recently, however, Johnson et al. (in press, Injury) presented an empirical counterargument that we believe is new. This counterargument is brutally honest and somewhat shocking (to us, anyway).
Johnson and colleagues start off by defining the p-value and its purpose:
“The primary purpose of using a P value is to minimize type I errors — erroneous conclusions made about differences between groups when no such difference truly exists. The type I error rate is often specified a priori at 0.05, meaning that there is a 1 in 20 chance — or a 5% risk — that the difference detected is because of chance rather than attributed to the effects of the intervention.”
This is not a particularly great start to a paper about p-values. First, several prominent statisticians such as Sir Ronald Fisher and Sir David Cox believed that the main purpose of the p-value is to quantify evidence against the null hypothesis instead of minimizing (“controlling” is a better word) Type I errors. For instance, Cox (1982) wrote “we use P as a measure of evidence, not as a basis for immediate tangible action” (p. 326). Second, the definition of the p-value provided by the authors is wrong: this is in our view perhaps the misconception that is the hardest to eradicate, the actual probability of obtaining a false positive result with P-values of around .05 is not equal to P but depends crucially on the prior probability that the alternative hypothesis is true (see Figure 1).
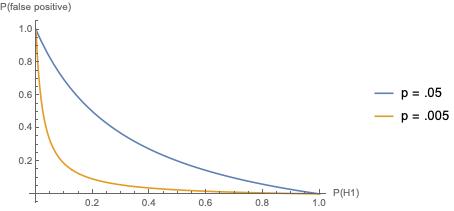
Figure 1: Probability of false positives for values of P(H1) with a power of .80
But these are just quibbles — after all, how many researchers are aware of the definition and the historical purpose of the p-value? The topic of this post is the empirical argument that the authors bring to bear.
The authors examined 48 randomized clinical trials (RCTs) with 124 primary endpoints. Of these endpoints, 39.5% (49/124) had a p-value of less than .05. Half of these “statistically significant” p-values fell in the disputed area between .05 and .005, the evidentiary no-man’s land where the “Redefine Statistical Significance” article would have them be reclassified as “suggestive” rather than “significant”. This is an interesting empirical finding that should give us cause for concern: apparently, in the field of orthopaedic trauma RCTs, about half of the findings confidently presented as “significant” provide statistical evidence against the null hypothesis that is only weak. When such weak evidence is used to motivate changes in medical procedures, this can be really dangerous for all those involved, most notably patients. However, the conclusion that the authors draw in the abstract is as follows:
“Based on our results, adopting a lower threshold of significance would heavily alter the significance of orthopaedic trauma RCTs and should be further evaluated and cautiously considered when viewing the effect such a proposal on orthopaedic practice.”
So there you have it. The authors do not argue that it is problematic for weak evidence to be confidently presented as a reason to “reject the null hypothesis”. Neither do the authors argue for reporting a consistent and interpretable quantitative measure of evidence (e.g., a Bayes factor or likelihood ratio). No, the fact that about half of the P<.05 orthopaedic trauma RCTs provide only weak evidence is reason to cautiously evaluate… not those RCTs, but the proposal to reclassify those findings as “suggestive”!
It should be acknowledged that the authors provide a more cautious evaluation in the body of their article. Their final paragraph:
“In conclusion, lowering the P value to .005 may address some shortcomings of RCTs in orthopaedics. A lower P value threshold may be a promising temporizing measure to improve RCT methodology and general reproducibility of findings (De Ruiter, 2019) until more permanent solutions are found, which could take considerable time to implement. Adopting a lower threshold of significance would heavily alter the interpretation of orthopaedic trauma RCTs. Caution is thus warranted regarding the effects of such interpretations on clinical decision making.“
We agree with everything the authors write here, except for the final sentence. Caution is indeed warranted, but it should be directed at the RCTs that motivated researchers to draw strong, absolute, all-or-none conclusions from evidence that is only weak. In our opinion, calling weak evidence “suggestive” instead of “significant” can only help, not hurt.
References
Benjamin, D. J. et al. (2018). Redefine statistical significance. Nature Human Behaviour, 2, 6-10.
Cox, D. R. (1982). Statistical significance tests. British Journal of Clinical Pharmacology, 14, 325-331.
De Ruiter, J.P. (2019). Redefine or justify? Comments on the alpha debate. Psychonomic Bulletin & Review, 26(2), 430-433.
Johnson, A. L., Evans, S., Checketts, J. X., Scott, J. T., Wayant, C., Johnson, M., Norris, B., Vassar, M. (in press). Effects of a proposal to alter the statistical significance threshold on previously published orthopaedic trauma randomized controlled trials. Injury.
About The Authors

J.P. de Ruiter
J.P. de Ruiter is the Bridge Professor in the Cognitive Sciences at Tufts
University (Medford, Massachusetts).

Eric-Jan Wagenmakers
Eric-Jan (EJ) Wagenmakers is professor at the Psychological Methods Group at the University of Amsterdam.


