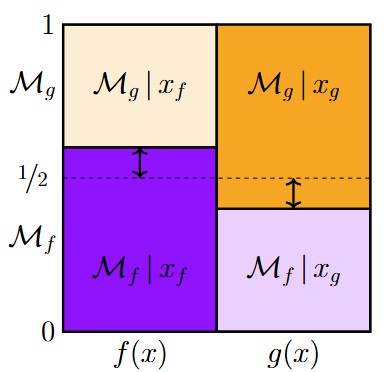
From P-values to Bayes Factors with eJAB

This post is a teaser for Velidi, P., Wei, Z., Kalaria, S. N., Liu, Y., Laumont, C. M., Nelson, B. H., & Nathoo, F. S. (2025). Generalized Jeffreys’s approximate objective Bayes factor: Model-selection consistency, finite-sample accuracy, and statistical evidence in 71,126 clinical trial findings. ArXiv preprint:2510.10358. Abstract “Concerns about the misuse and misinterpretation of p-values and statistical significance have motivated…
read more