
I was exhausted and expecting my newborn to wake up any moment, but I wanted to look at the data. I had stopped data collection a month prior, and wasn’t due back at work for weeks, so it could have waited, but my academic brain was beginning to stir after what seemed like eons of pregnancy leave. Sneaking a peek at my still sleeping daughter, I downloaded the .csv from Qualtrics. I made columns for the independent variables, splitting the 6 conditions in half, and then fed the data into JASP. I had run the Bayesian ANOVA in JASP before, for the pilot study, and used the program for years before that, so I knew the interface by heart. I had my results, complete with a plot, within seconds.
The output wasn’t what I had expected or hoped for. It certainly wasn’t what our pilot had predicted. The inclusion Bayes factors were hovering around 1 and the plot with its huge error bars and strangely oriented lines were all wrong. Maybe I’d made a mistake. I had been in a rush after all, I reasoned, and could have easily mixed up the conditions. Several checks later, I was looking at the same wrong results through tear-filled eyes.
From the beginning, I had believed so completely in the effect we were attempting to capture. I thought it was a given that people would find the results of a registered report (RR) more trustworthy than those of a preregistration (PR), and that the PR results would be yet more trustworthy than those published `traditionally’ with no registration at all. Adding a layer of complexity to the design, we had considered familiarity for each level of registration. We expected that results reported by a familiar colleague would be more trustworthy than those of an unfamiliar person. Logical hypotheses, right? To me they were.
Between the pilot and the full study, we had successfully recruited over 600 academics to respond to a short study, where we manipulated PR/RR and familiarity across conditions. Each participant was given one of six short fictional study vignettes, complete with simulated results and a plot of the data. They then provided a trustworthiness rating on a scale from 1 to 9. The stimuli in the pilot were simple and elegant, including only the bare basics of the fictional study. Based on qualitative data gathered in the pilot, the full study stimuli had been designed more elaborately; a proxy for the experience of reviewing a real study.
Although the pilot results were messy, the result was as we had predicted. The effect of our primary IV — PR/RR — was compelling, the inclusion Bayes factor over 1,400. The plot (Figure 1) suggests that participants found the results of a registered report authored by a familiar colleague most trustworthy, in comparison with studies not registered at all. The full study (plot in Figure 2) results told a different story, with huge error bars and ambiguous inclusion Bayes factors for both independent variables.
There were likely good reasons for the differences between the pilot and full studies. For one, the materials were different. Two co-authors were strongly against making the stimulus vignettes more complex, preferring to keep the pared-back materials of the pilot. It is likely that more reading time and more detailed materials made for less focused or committed participants.
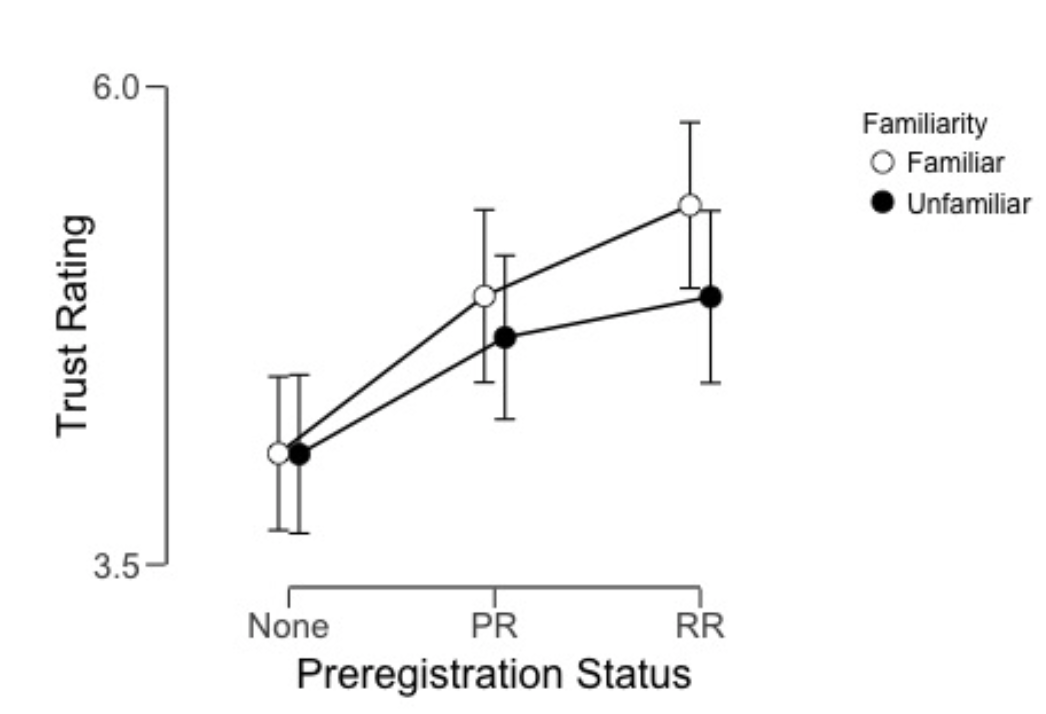
Figure 1. Plotted data of the pilot study (N = 402) after exclusions.
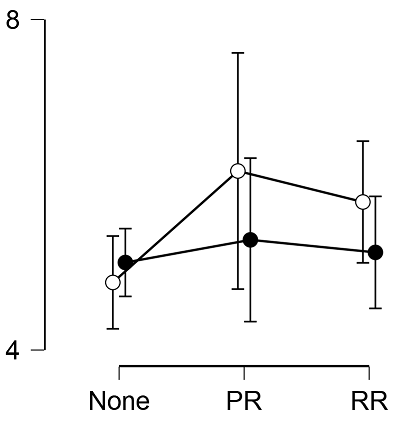
Figure 2. Plotted data of the full study (N = 209) after exclusions.
For another thing, the discussion surrounding PR/RR has evolved since the initial conception of the study, and even since the pilot was run (in 2015 and 2017, respectively). Twitter has captured much of this discussion. Around the initial popularization of PR/RR, the discussion seemed somewhat simpler. Early supporters were either strong, vocal advocates, while some were just beginning to hear of it, or had no idea. Recent debates focus more on the complexities and limitations of PR and RR, and many statements start with “they’re good initiatives, but…”.
The study had other issues too. After the initial data collection period for the full study was over, I realised that we would not have enough data per design cell to meet our original sampling plan. I collected more data, but after excluding incomplete datasets and people who’d failed the manipulation checks, we had lost about 86% of our data.
I had gone through the data over and over again for coding, exclusion and programming mistakes with two co-authors, and had run and re-run the analysis. One evening, I was dejectedly talking to my partner about the mess that was the study I had worked so hard on for literally years1. Pragmatic Dutchman that he is, he responded with something like “…but it’s a registered report, right?’’ Then the penny dropped. I had been so focused on the `failed’ experiment that I had neglected to see the value the report could still have.
The publication, now available online at https://royalsocietypublishing.org/doi/10.1098/rsos.181351, highlights two important points for consideration of PR and RR.
- The registered report model publishing model allows messy, confusing results like ours see the light of day2. We worked hard on creating a design and stimuli which would test our hypotheses, and had help from thoughtful, critical reviewers during the process. In contrast, in the traditional publishing system, carefully planned methodology and sensible analyses often don’t matter in the face of inconclusive or null findings.
Widespread use of registered reports (providing they undergo careful peer review, editorial scrutiny and adhere closely to plans) can bring the social sciences literature to a place where it is a faithful representation of psychological phenomena. The registered report format gives us a way to publish all research that is conducted, not just those that are neat and sexy.
As a PhD student, this is especially relevant. You want your (mostly figurative) blood, sweat and tears to count in the ways that matter greatly to many people: possibly your thesis defence panel, future hiring committees, and the archaic publishing system which still largely rules academia.
- When authors don’t have to worry about trying to repackage and sell an ugly study that didn’t go to plan, they’re free to be transparent about what went wrong, and can provide a valuable methodological guide for others who might want to study the same effect. This is especially important in fields where resources are a problem; where studies are expensive or time consuming, or subjects are difficult to come by (e.g., certain rare disease patient groups) or work with (e.g., babies).
Sceptics like to say that PR and RR are not a panacea. Indeed, though most advocates don’t tout them as such. PR and RR can still be `hacked’ and misused, and they don’t cover all research sins. PR is especially sensitive to cheating, as preregistration documents aren’t scrutinized and checked like RR proposals and final manuscripts are.
I think of the Droste effect when I think of this study and my experience as its first author. We started out with a registered report which tried to find evidence for one benefit of registered reports (more trustworthy results, or at least the perception), and ended up highlighting other benefits. Thanks to having in principle acceptance with Royal Society Open Science, we could report the results with complete transparency and still publish what we had done. Now, with a healthy 15-month-old, more balanced perspectives, and a little distance, I couldn’t be prouder of this study.
Notes
1 Although I know of some studies that have spanned more than a decade, three years is almost a lifetime when you’re only a PhD student.
2 You could argue that a preprint would have a comparable effect. While this is strictly true, I would argue that a peer-reviewed publication in a trustworthy journal where the planned methods and analyses have been scrutinized by the traditional editor-reviewer combination is a superior option, both in terms of the study’s potential quality and the traction it will make with its target market.
About The Author

Sarahanne M. Field
Sarahanne M. Field is a PhD candidate doing meta scientific research at the University of Groningen, the Netherlands.


