
Recently the 59th annual meeting of the Psychonomic Society in New Orleans played host to an interesting series of talks on how statistical methods should interact with the practice of science. Some speakers discussed exploratory model building, suggesting that this activity may not benefit much, if any at all, from preregistration. On the Twitterverse, reports of these talks provoked an interesting discussion between supporters and detractors of preregistration for the purpose of model building. Below we describe the most relevant presentations, point to some interesting threads on Twitter, and then provide our own perspective.
The debate started when Twitter got wind of the fact that my [EJ] mentor and intellectual giant Rich Shiffrin was arguing against preregistration (his slides have also been made available, thanks to both Rich and Trish Van Zandt). Here is the abstract of his talk “Science Should Govern the Practice of Statistics”:
“Although there are two sides to these complex issues, this talk will make the case for the scientific judgment side of the ledger. I will I argue that statistics should serve science and should be consistent with scientific judgment that historically has produced progress. I argue against one-size-fits-all statistical criteria, against the view that a fundamental scientific goal should be reproducibility, and against the suppression of irreproducible results. I note that replications should on average produce smaller sized effects than initial reports, even when science is done as well as possible. I make a case that science is post hoc and that most progress occurs when unexpected results are found (and hence against the case for general use of pre-registration). I argue that much scientific progress is often due to production of causal accounts of processes underlying observed data, often instantiated as quantitative models, but aimed at explaining qualitative patterns across many conditions, in contrast to well defined descriptive statistical models.”
We have never grasped Rich’s argument. Preregistration and other open-science tools serve merely as gratis protection against the biases that beset all human beings. Preregistration helps keep researchers honest, both to their peers and to themselves. Moreover, some of Rich’s issues may stem from misconceptions about preregistration. For example, from within the slides of Rich’s talk:

The well-known retort is that preregistration does not preclude exploratory analyses nor does it preclude serendipity, meaning that preregistration in no way restricts the focus to only “expected” results. Therefore, in the fragment from the abstract “I make a case that science is post hoc and that most progress occurs when unexpected results are found (and hence against the case for general use of pre-registration)”, the “hence” does not follow. The point of preregistration not being restrictive was eloquently expressed in a recent tweet by Cameron Brick (@CameronBrick), who pointed out that preregistration is not a “prison of plans”, and instead is about transparency:

Rich also suggested that preregistration is not free, but instead comes at a high cost:

Firstly, Rich appears to confuse the general process of preregistration with the more specific journal format of [pre]Registered Reports. Registered Reports, which Rich appears to be referring to, are a specific type of article offered by some journals that allow authors to have their experimental and analysis methodology peer-reviewed and accepted before data collection, in an attempt to increase transparency and reduce issues such as the file drawer problem (for an overview see https://osf.io/rr/). In contrast, preregistration is the more general activity where the experimental and analysis plans of the researcher/s are recorded and publicly archived, so that confirmatory and exploratory analyses can be more easily distinguished. Importantly, the general process of preregistration does not require the experimental and analysis plans to be peer-reviewed, meaning that preregistration itself imposes no additional burden on the peer-review system.
Even in the more specific case of Registered Reports, we still believe that Rich may misjudge the situation. Reviewers already assess the merits of a study in the standard review system, and Registered Reports allows these concerns to be raised before the study is conducted and for the authors to correct these issues, rather than the article being rejected or further data collection being required. Registered Reports, when performed properly, have the potential to reduce the burden on the peer-review system, preventing long articles from going through multiple rejections and/or rounds of revisions at multiple journals.
I [EJ] consider myself fortunate to know Rich well, and I suspect that when we are confronted with actual concrete experiments or models, Rich will be more critical and skeptical than I am (!). And we also believe that if Rich would try out preregistration himself, he would actually enjoy it a great deal (but perhaps only to make fun of it). A recent presentation of Rich on this topic is available online.
On Twitter, Simon Farrell (@psy_farrell), my [EJ] friend and fellow-postdoc from days of yore, posted a thread on Rich’s presentation, from which we show the first part:
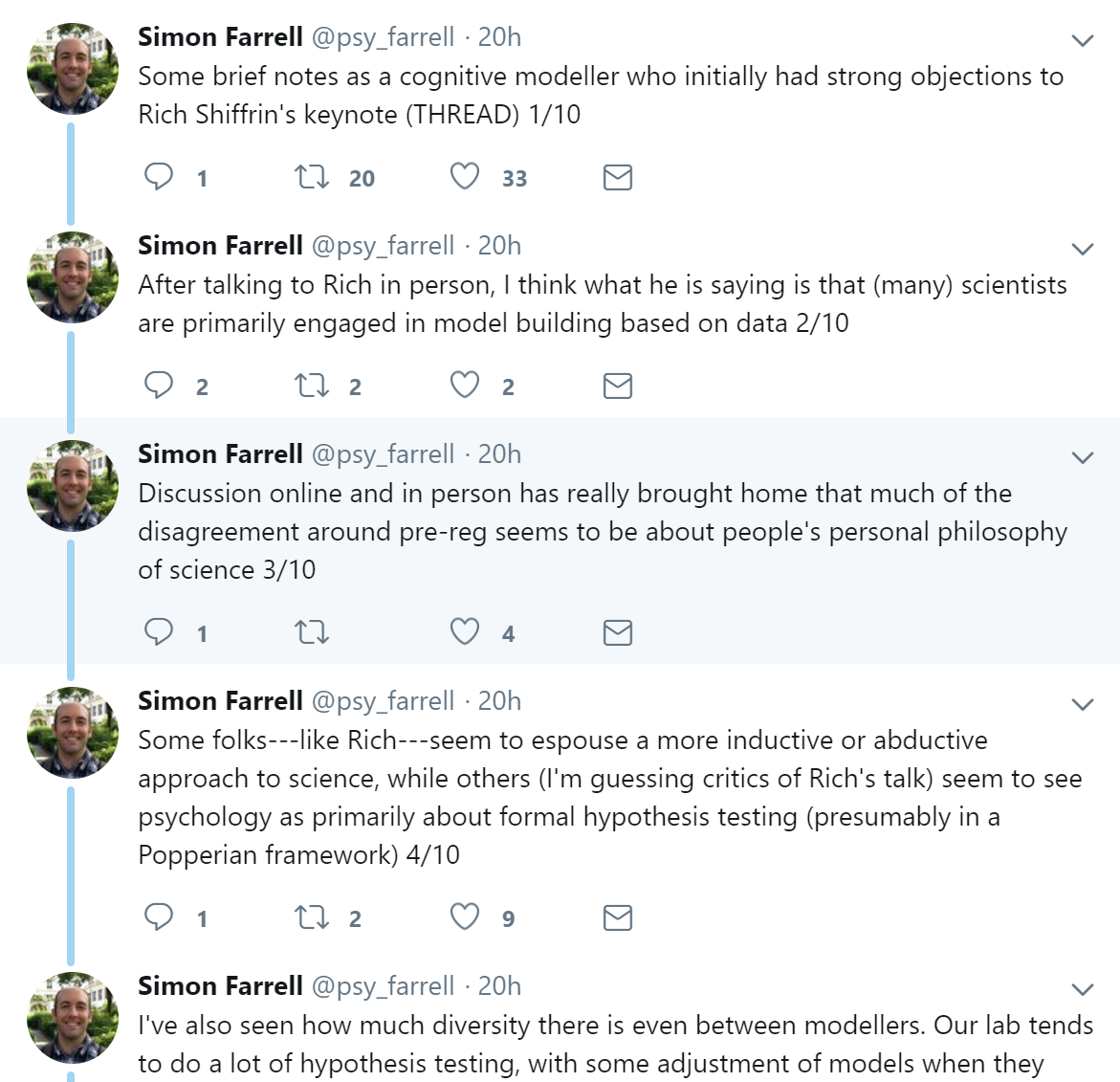
You get the gist: the idea is that preregistration is useful only for particular kinds of science; in the guessing phase of the scientific process (abduction means guessing or judging pursuitworthiness, see McKaughan, 2008) preregistration may be less useful. We agree, but the danger is that the results from the guessing phase will be interpreted as hard support or compelling evidence, not as an interesting suggestion that requires further rigorous assessment for it to be even tentatively accepted. Before explaining our concerns in more detail, let’s turn to a related talk, one by the amazing Trish Van Zandt. We have always looked up to Trish, and her Twitter handle (DoMoreMath @TrishaVZ) makes me [EJ] feel a little guilty and inferior. Which I am sure I am. Anyway, together with Steve MacEachern, Trish gave a presentation called “Breaking Out of Tradition: Statistical Innovation in Psychological Science”. This is the abstract:
“An insistence on p-values that meet arbitrary criteria for publication has resulted in the current replication crisis. This misapplication of statistical methods can be tied directly to a failure of statistics education in psychological science. Not only must we reconsider the statistics curriculum in our graduate programs, but we argue that we must change our focus to those methods that (a) permit the construction of hierarchical models that allow us to explain a range individual differences under a common theoretical umbrella, and (b) move us away from procedures that emphasize asymptotic models (such as the GLM) over theory-driven models. Finally, we need to emphasize the discovery of qualitative patterns in data over quantitative differences across groups, which leave open the question determining the size of a practically meaningful difference. Bayesian methods provide ways to address these difficulties. In this talk, we discuss how Bayesian models incorporate meaningful theory, and how hierarchical structures are flexible enough to explain a wide range of individual differences”
This all sounds eminently sensible. Trish has made her presentation publicly available at https://github.com/trishvz/Psychonomics2018. We looked at the slides and basically agreed with everything. In particular, these are Trish’s conclusions:

Trish also mentioned preregistration:

The argument, it appears, is that there will always be unexpected patterns in the data, and a careful statistician needs to adopt a model that is appropriate for the situation at hand. The danger, of course, is that allowing modelers this flexibility opens a pandora’s box of biases. We want to use appropriate models, but we do not want analyses that are certain to support the researchers’ pet theory. In a recent paper with Gilles Dutilh, Joachim Vandekerckhove, and others, we [EJ] combined preregistration with blinding; the preregistration document outlined the job of the modeler, but the modeler received a data set that was altered — the key dependent variable was shuffled, so that the modeler was free to select an appropriate model, but could not torture the data, the model, or both in order to obtain a desirable result (Dutilh et al., 2017). The point is that there are ways to open pandora’s box while keeping the demons and diseases behind lock and key [interestingly, Trish actually mentions in her talk that physicists do blinded analysis, but she did not seem to think highly of it].
More generally, we would argue that a preregistration document is not a law — violating the preregistered plan is not a capital offense. All that happens is that you have to be honest and say that the data invalidated the plan, and you created a new (hopefully similar) plan to accommodate the unexpected results. Many of my [EJ] own preregistered experiments have a section “deviation from the preregistration document” — preregistration is about honesty, not about dogmatism.
Overall, though, we can live with the conclusion that there are ways to improve on preregistration. Weirdly, my [EJ] impression from Trish’s slides did not match the Twitter reports of her presentation, where she had been said to be more critical of preregistration. And indeed, Trish tweeted:

Woh, this is indeed more critical! Preregistration of experimental procedures may make “some sense”, but preregistration of models “will not serve any useful purpose”. Our own opinion is closer to “If you don’t want to mislead yourself and others with inferential statistics, you’d better preregister whatever you set out to do”. More about that later. Trish has written out her entire presentation and you can read it here.
Like sharks ripping apart the rotting carcass of the idea formerly known as preregistration, other researchers whom we greatly respect joined the feeding frenzy. First, there was the brilliant Danielle Navarro (@djnavarro). In the first tweet below, Danielle refers to a paper that you can access here:
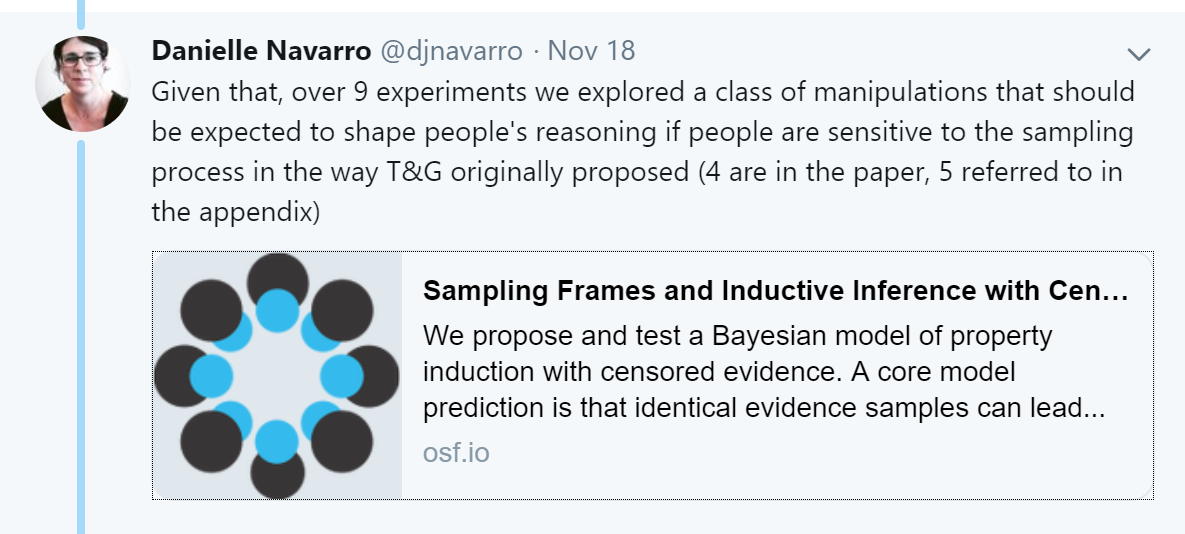
She then continues:
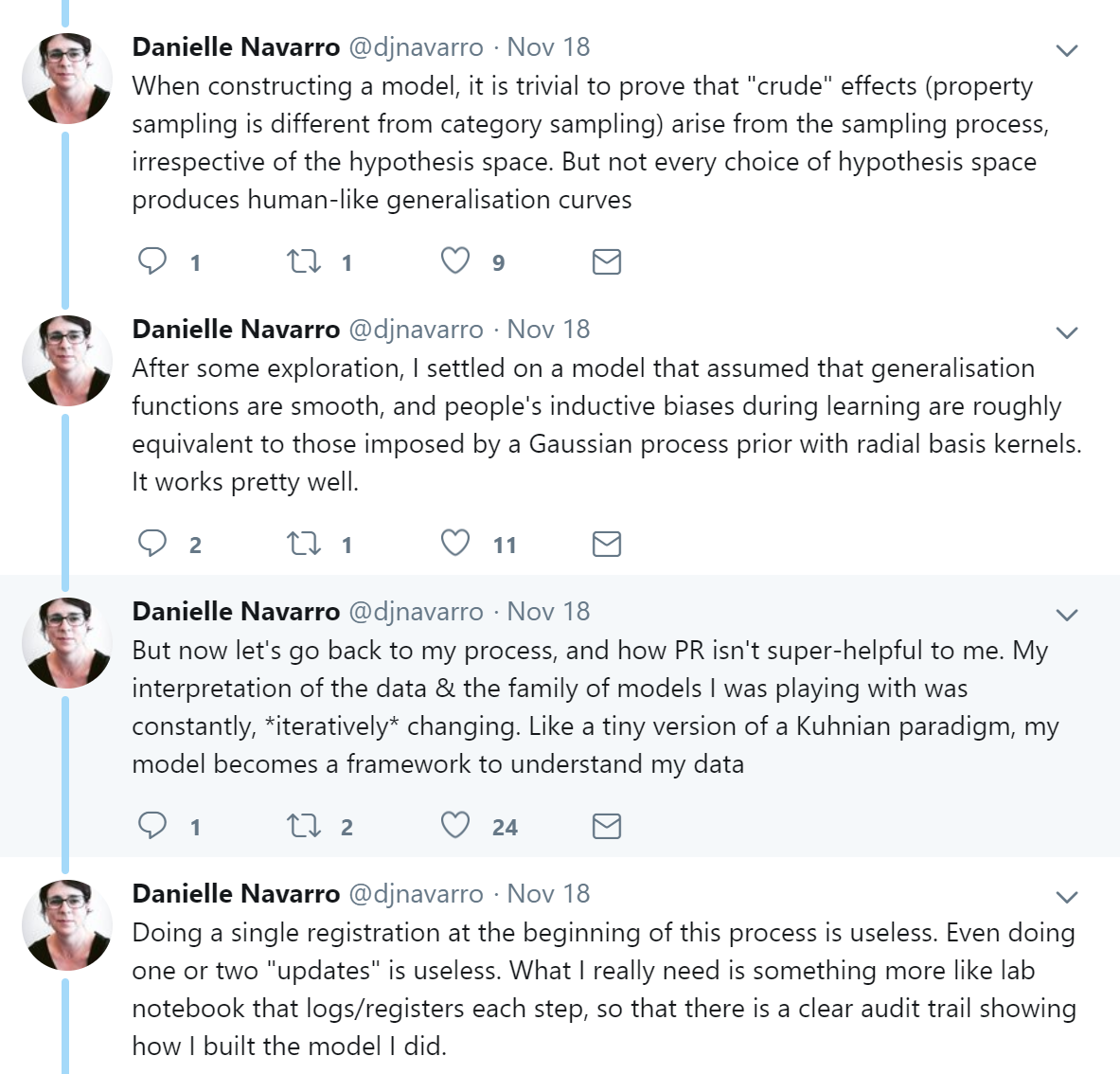
Although we agree that a “lab notebook” that provides a clear audit trail seems like an excellent idea for situations like exploratory model building, the natural first step for this trail seems as though it would be the researcher recording their initial thoughts and directions about building the model. Recording the initial thoughts and directions is merely an informal version of preregistration, meaning that mastering preregistration in exploratory model building seems like a clear initial step towards creating a more intricate complete log of everything that was done in the model building process.
And then another shark, long-time collaborator Richard Morey (@richarddmorey), also joined the discussion:

Before providing our own perspective, an interesting defense of preregistration was provided by Michael Frank (@mcxfrank) — we recommend the entire thread, but here we’ll just show the starting tweet and the concluding one:
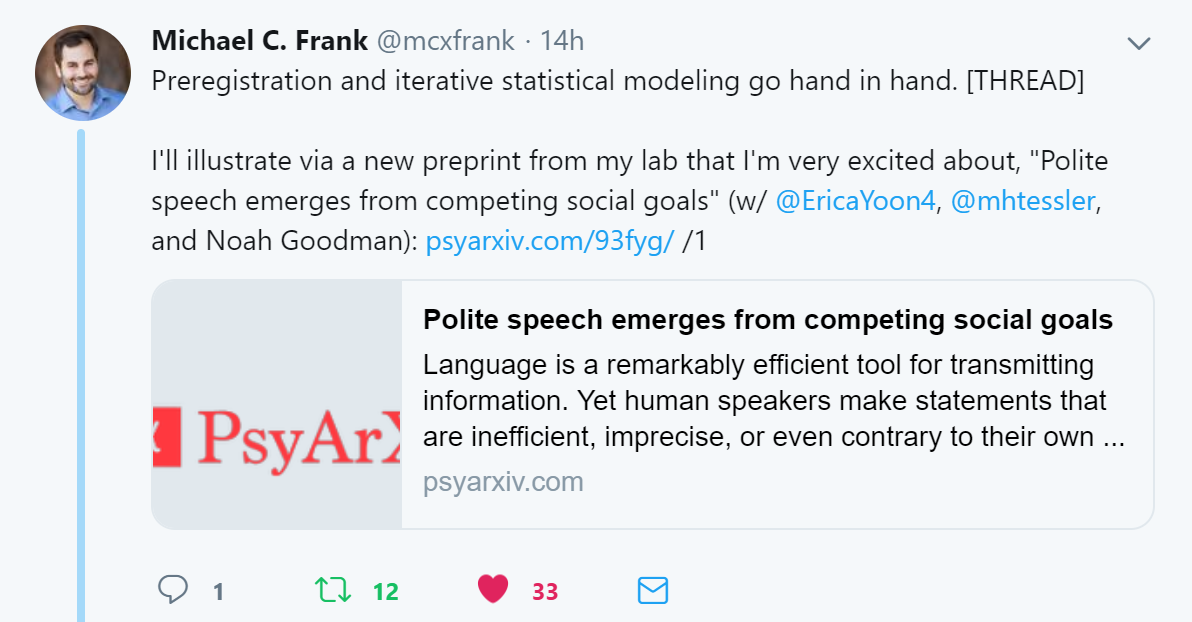

We believe that Michael makes a key point here, which we cannot emphasize enough: iteratively assessing what models can/cannot explain in a sample of data is a broader form of the classic issue of overfitting. If you assess an infinite number of models in their ability to account for a sample of data, then the overall exploratory model building exercise has infinite flexibility, although the “final model” selected may itself not be infinitely flexible. Therefore, if a researcher is to iteratively construct their model in an exploratory manner, then the ability to account for this overfit sample of data provides little evidence in favor of a model, and further validation is required in new samples of data.
A few days ago, the Rouder shark joined with the blog post “Preregistration: Try it (Or not)”. Everything that Jeff has written is thought-provoking — we’re a huge fan of his work and how he practices science. Here we’ve copy-pasted the part that is most relevant for the current discussion:

Our Own Perspective on the Role of Preregistration in Modeling
What is the role of preregistration in exploratory model building? Well, it is the same as in any exploratory enterprise: if the goal is purely exploratory, then there is absolutely no urgent need to preregister. You can do whatever you want: try different models, consider different dependent variables, select particular experiments and participants, etc. Of course, such total flexibility comes at a price: the usual inferential statistics are no longer interpretable. You are free to compute a p-value, a confidence interval, a BIC, a Bayes factor, or a credible interval. You just have to realize that they have lost their meaning (De Groot, 1956/2014).
The fact that ruthless exploration (and without preregistration, how can anybody tell how ruthless the exploration really was?) invalidates all statistical inference should not come as a surprise. For frequentists, exploration creates a multiple comparisons problem with the number of comparisons unknown (De Groot, 1956/2014). For Bayesians, exploration means that some data are deliberately left unreported (which affects the likelihood) and that a priori unlikely models may receive a double-update from the same data (which affects the prior): the first update is informal and identifies the unlikely model as worth exploring (“hey, it looks like a mixture with skewed contaminants and removal of trends might do the job”); the second update is formal and re-uses the same data that spawned the model in the first update to test that model (“lookie here! A model with skewed contaminants and removal of trends outperforms the competition”). No wonder the model comes out of this “test” looking pretty good. A Bayesian robot could avoid the double-update and reset its wires to the state it was in before it saw the data. Unfortunately, humans do not have such mental time travel prowess, and their memories of what they thought in the past is inevitable polluted by hindsight bias.
In sum, in exploratory model building you can do whatever you like. The only thing you are not allowed to do is interpret any of your inferential statistics. The exploratory character of the statistical analysis has utterly destroyed their meaning. We believe that it is not properly recognized how deep this goes, and we believe that many researchers who advocate and promote “exploratory model building” would in the end like to draw some conclusion about their models other than “this is an interesting model for the present sample and future work ought to determine whether any of this makes any sense at all”. For this reason alone, we believe that exploratory model building does benefit from preregistration. The preregistration form could read: “We will attempt to devise a model for task such-and-so. This will be a purely exploratory exercise and therefore none of our inferential statistical analyses are interpretable. We will just present them for you to ignore” Such a preregistration form would prevent researchers from giving in to temptation and interpret the results of their statistical analyses, effectively pretending that the exploratory enterprise was confirmatory.
The foregoing may seem extreme. But now consider the case of Dr. C. deVille who has just proposed Sequential Position Of Traces (SPOT) a radical new memory model. Dr. deVille now starts a research programme to explore extension of SPOT in several paradigms and under several conditions. Imagine the following scenarios:
(1) SPOT predicts a positive correlation between personality characteristics and the ability to discriminate highly similar stimuli. Dr. deVille’s next paper presents a correlation. What do you think — will it be negative, absent, or positive? Do you think the analysis was conducted “judiciously”, based on “good judgment”? Does it matter that Dr. deVille was extending her model instead of applying an ANOVA? In our opinion, people are people, and biases affect all of us, both explicitly and implicitly. It is hubris to think that modelers can somehow immune to the bias that plagues the defenseless experimentalists. In fact, one among many documented biases is the “bias blind spot”, the idea that you believe that everybody else to be more biased than you. [no, the experiments that showed this were not preregistered]
(2) Dr. deVille finds that her model account successfully for phenomena A, B, and C. She also explores phenomena D and E, but the model does not fare so well there. In her next paper, does Dr. deVille report only the results for A, B, and C, or does she also acknowledge that the model does not work well for D and E?
(3) Dr. deVille has access to a series of five experiments, all from different paradigms. Two out of the five experiments provide data that allow her model to be successfully extended and outperform existing models. The extension does not work well for the remaining three experiments. In her next paper, will Dr. deVille report all experiments or only the ones that “worked”?
(4) Dr. deVille finds that her model works like a charm, except for participants who own dogs. Upon reflection, Dr. deVille realizes SPOT can be adjusted to handle this aspect of the data; the resulting article states that SPOT predicts the effects to appear only for people who do not own dogs. Does Dr. deVille mention that the adjustment of SPOT was motivated by the data?
(5) Dr. deVille finds that her model provides a compelling result when a test of direction is entertained, but an ambiguous result when a test against a point-null is entertained. Which test will Dr. deVille report and emphasize?
A brief glance at the literature suggests that researchers feel very strongly about their models. The modelers that we know are emotionally deeply invested in their work, and they care deeply about the future of their brainchildren. And there is little wrong with enthusiasm, except that, when left unchecked, it opens the doors for motivated reasoning, confirmation bias, and several other biases and fallacies that have clouded human judgment since the dawn of time.
We find it remarkable that modelers resist the idea that, just like any other human being, they are susceptible to biases and fallacies. We have witnessed examples of computational modeling, published in the most prestigious journals, where it is immediately clear that the results have been obtained more by the ingenuity of the modeler than by the inherent quality of the model. The consequences for the field, of course, are dire.
A Reprieve for Exploratory Model Building
Although our discussion has been critical of the resistance to preregistration in computational modelling, we do believe that there is merit to the point that preregistration should not be a one-size-fits-all approach that all researchers must always use. Below we discuss some of these points, but also note where preregistration might still serve a purpose.
Firstly, model building that is completely exploratory (i.e., little-to-no a-priori intentions, and going where the data takes you) can be useful in new fields where no models currently exist to explain the processes. As discussed by Chris Donkin in his talk during the same session as Rich/Morey/Trish, there are many situations where we know very little about a phenomenon, and these situations may be best begun with exploration and estimation. Given no basis to start from, how do we develop a model of a phenomenon? The “iterative updating” approach mentioned by Danielle Navarro seems as though it would be the most efficient way to develop a model, where a researcher assesses what works (and what doesn’t) in their sample of data, and begins to form ideas of what’s going on. As mentioned by Michael Frank, this would be a very flexible process that would overfit to the sample of data, and so any evidence for a model resulting from the exploratory building process should be taken with a grain of salt, and the best models should be validated in new samples of data.
Secondly, we agree that in some situations preregistration might be less useful than in other situations. We believe that calling preregistration useless is a somewhat naïve perspective, but we also believe that it would be just as naïve of us to claim that preregistration is equally useful in all situations. Exploratory model building is likely one of the situations where preregistration is (initially) less useful, and the cost (i.e., time) of preregistering the exercise may outweigh any potential benefits. However, we believe that after model development, the model should then be tested on subsequent data, and compared to other potential models. This subsequent model testing is a situation where preregistration becomes extremely useful, as researchers can specify exactly how they plan to test a model, or how they plan to compare several models, limiting the researcher degrees of freedom to influence the outcome of the assessment. The application of models as measurement tools (e.g., the primary use of response time models such as the diffusion model) also provide a clear situation where preregistration is extremely useful, as researchers should know a-priori how they plan to apply the model, and what theories they are testing.
To build on the previous point, in some situations (such as exploratory model building) the preregistration document may end up being of little use, as it may be completely violated by the end of the exercise. However, was the process of attempting to develop as many ideas as possible a-priori also useless? Although it may be in some situations (such as the first point, where there is little-to-no previous knowledge to build off without having observed the current data), we believe that this initial “drawing-board process” may be useful in many situations, and that in the process of attempting to create a formal preregistration document, researchers may realize that they know more than they originally thought, and find a clear and systematic way of building a model based on the data patterns that they may/may not find.
Lastly, although we believe with Cameron Brick that preregistration is not a “prison of plans”, we acknowledge that some researchers may not subscribe to this view of preregistration (i.e., they may believe that the preregistration document must be adhered to in all situations), which may be the cause of some of the disdain towards preregistration. We agree that in situations where reviewers force researchers to completely abide by the preregistration document, as if it were the word of law and no alternative action is allowed, then preregistration becomes a limited approach, especially in the case of computational modelling and model building. Specifically, the approach of “preregistration as a prison of plans” – which we strongly disagree with, and we believe that most within the scientific community disagree with as well – would greatly limit the modelling process, preventing researchers from publishing sensible, common, and transparent practices because of issues that they did not envisage a-priori. However, rather than abandoning preregistration because some view the document as a prison, we believe that the best way to prevent the “preregistration as a prison of plans” approach is increase the amount of discussion on preregistration (such as our discussion here, and all of the valuable points made by others that we mention within our discussion), so that the best practices for preregistration can be found for each specific area of research. Importantly, if editors and reviewers of preregistered modelling papers are explicitly aware that violating the preregistration document is perfectly OK when justified, then preregistration provides little constraint on what modellers are allowed to do (except to help prevent questionable research practices).
A Brief Summary for a Not-So-Brief Discussion
Our discussion has been lengthy, detailing many interesting points made by many different researchers. Here, we attempt to provide a brief summary of the discussion with the points made against pre-registration, and a brief response as to why we disagree.
Point 1: Preregistration is of little value as science is largely posthoc.
Response: Preregistration does not need to be restrictive, and researchers should be allowed to extend from, or even violate, the preregistration document in situations where it is deemed necessary. Preregistration simply allows the a-priori predictions to be separated from the posthoc exploration in a transparent manner. Also note that it is debatable whether science is “largely posthoc”, though we chose to avoid debating this here.
Point 2: Preregistration imposes an additional burden on science as reviewers have to judge the merit of the proposed study.
Response: The general process of preregistration does not place an additional burden on the peer-review system, as preregistration documents do not need to be peer-reviewed. Although the more specific [pre]Registered Reports (a new type of journal article
Point 3: Preregistration can be useless, and a better approach is to provide a complete record of the model building process.
Response: We agree that preregistration can be more useful in some situations than others, and that a complete record of the model building process would be a fantastic step forward for transparency. However, we believe that the first step to a complete record of the model building process is to record the initial thoughts and directions of the researcher, which is exactly what preregistration is. Therefore, preregistration seem like the natural method to extend, piece by piece, until it becomes the “complete record of the model building process” suggested. Also, it should be noted that we believe iteratively assessing what models can/cannot explain a sample of data is a broader form of the classic issue of overfitting, and that the ability to explain the trends in a highly explored data set should be taken with a grain of salt.
Where to Go from Here
We find ourselves in a somewhat uncomfortable situation. On the one hand, most of our peers, friends, and mentors in mathematical psychology tell us that preregistration serves no function in exploratory modeling building. On the other hand, we have rarely come across a modeling paper that honestly reports “we were just forking around with the model until something worked, so please ignore our inferential statistics, there is no way to tell whether any of this stuff generalizes”. We may be well the ones who are mistaken here — perhaps the laws of scientific learning are warped in the vicinity of sagacity. But it is also possible that our esteemed modeling friends find it difficult to accept that their artful modeling work will benefit from articulating an advance plan of attack.
Luckily, we think this is an issue that can be resolved. We are all part of one big modeling family, and several ways are open for an informative and constructive exchange of ideas. First, some of us might actually try preregistration and report their experience. Second, we could engage in an adversarial collaboration between preregistration-enthusiasts and preregistration-skeptics (after writing this text, we learned that the wheels for this have been put in motion already). Third, we could enter a debate, perhaps for the new journal Computational Brain & Behavior (edited by the inimitable Scott Brown, @3rdincharge).
Another important issue to discuss in the future is the role of direct replication in computational modeling. Rich Shiffrin was generally highly critical of direction replication in his talk, suggesting that direct replication is the opposite of how science should operate. However, the Psychonomics plenary lecture of Hal Pashler gave a very different perspective, showing by example how direct replication is important in preventing false positives from becoming the cornerstone of future scientific research (see here). We look forward to constructive discussions on this topic in the future, as with the current discussion on preregistration.
References
De Groot, A. D. (1956/2014). The meaning of “significance” for different types of research. Translated and annotated by Eric-Jan Wagenmakers, Denny Borsboom, Josine Verhagen, Rogier Kievit, Marjan Bakker, Angelique Cramer, Dora Matzke, Don Mellenbergh, and Han L. J. van der Maas. Acta Psychologica, 148, 188-194. [preprint]
Dutilh, G., Vandekerckhove, J., Ly, A., Matzke, D., Pedroni, A., Frey, R., Rieskamp, J., & Wagenmakers, E.-J. (2017). A test of the diffusion model explanation for the worst performance rule using preregistration and blinding. Attention, Perception, & Psychophysics, 79, 713-725. [open access link]
McKaughan, D. J. (2008). From ugly duckling to swan: C. S. Peirce, abduction, and the pursuit of scientific theories. Transactions of the Charles S. Peirce Society, 44, 446-468.
About The Authors

Eric-Jan Wagenmakers
Eric-Jan (EJ) Wagenmakers is professor at the Psychological Methods Group at the University of Amsterdam.

Nathan Evans
Nathan Evans is a postdoc at the Psychological Methods Group at the University of Amsterdam.


