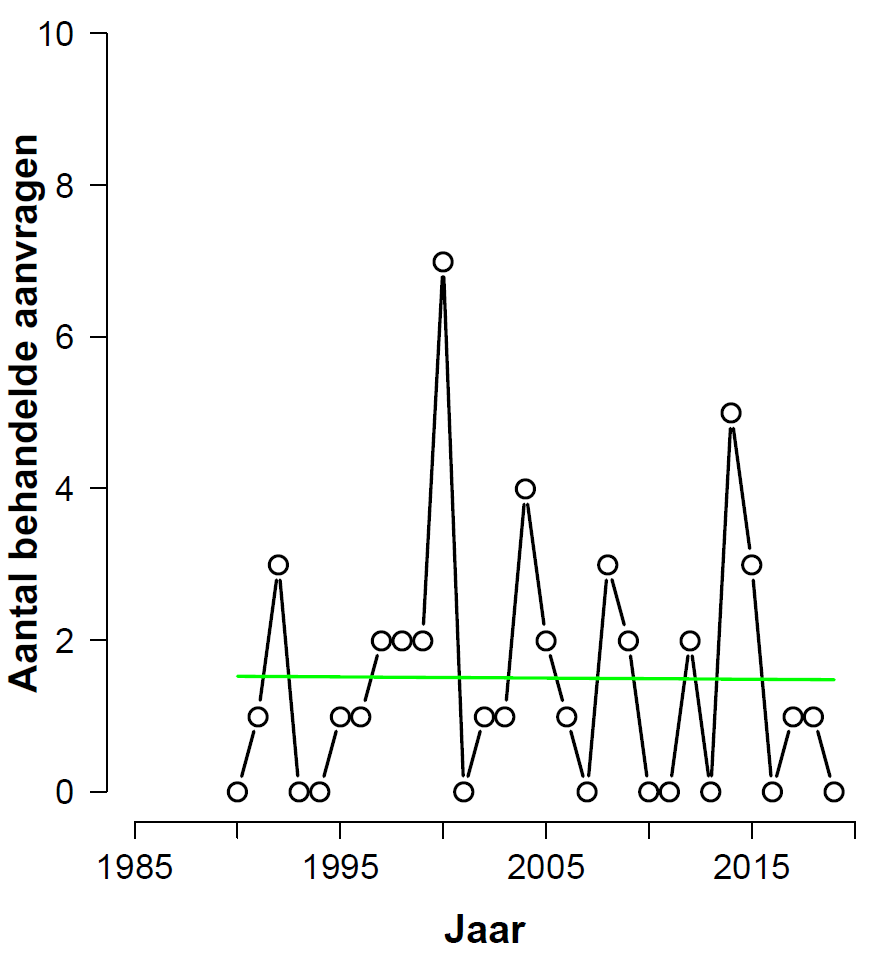
PROBABILITY DOES NOT EXIST (Part II)

In the previous post I discussed the famous de Finettti (1974) preface, containing the iconic statement “PROBABILITY DOES NOT EXIST”. As mentioned in that post, many statisticians and philosophers of science believe that, together with Frank Ramsey, de Finetti was the first real subjectivist. Fellow subjectivist Dennis Lindley, for instance, always expressed a fawning admiration for de Finetti, calling him…
read more