To my shame and regret, I only recently found the opportunity to read the book “Bayesian philosophy of science” (BPS), by Jan Sprenger and Stephan Hartmann. It turned out to be a wonderful book, both in appearance, typesetting, and in contents. The book confirmed many of my prior beliefs ;- ) but it also made me think about the more philosophical topics that I usually avoid thinking about. One example is “the problem of old evidence” (due to Glymour, 1980). Entire forests have been felled in order for philosophers to be able to debate the details of this problem.
Below I will provide my current perspective on this problem, considered by Sprenger and Hartmann to present “one of the most troubling and persistent challenges for Bayesian Confirmation Theory” (p. 132). It is highly likely that my argument is old, or even beside the point. I am not an expert on this particular problem. But first let’s outline the problem.
Old Evidence
In order to provide the correct context I will quote liberally from PBS:
The textbook example from the history of science is the precession of the perihelion of the planet Mercury (…). For a long time, Newtonian mechanics failed to account for this phenomenon; and postulated auxiliary hypotheses (e.g., the existence of another planet within the orbit of Mercury) failed to be confirmed. Einstein realized in the 1910s that his General Theory of Relativity (GTR) accounted for the perihelion shift. According to most physicists, explaining this “old evidence” (in the sense of data known previously) conferred a substantial degree of confirmation on GTR, perhaps even more than some pieces of novel evidence, such as Eddington’s 1919 solar eclipse observations. (…)
We can extract a general scheme (…): A phenomenon
is unexplained by the available scientific theories. At some point, it is discovered that theory
accounts for
PBS then presents the problem in the form of Bayes rule:
\begin{equation} p(T | E) = p(T) \frac{p(E | T)}{p(E)}, \end{equation}
and argue: “When 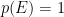
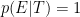
Issue 1: Old Evidence or Unrecognized Evidence?
From my perspective, the problem of old evidence does not highlight a limitation of Bayesian confirmation theory, but a limitation of the human intellect. To make this clear, let’s change the scenario such that
\begin{equation} \frac{p(E | T)}{p(E | \text{not-}T)} = 1, \end{equation}
that is, theory
Thus, it does not matter whether
\begin{equation} \frac{p(E | T)}{p(E | \text{not-}T)} >> 1. \end{equation}
The fault therefore appears to lie not with Bayesian confirmation theory, but with researchers not being omniscient.
Issue 2: p(E) = 1?
One may object that the equation immediately above is incorrect, as 
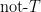
References
Glymour, C. (1980). Theory and evidence. Princeton, NJ: Princeton University Press.
Sprenger, J., & Hartmann, S. (2019). Bayesian philosophy of science. Oxford: Oxford University Press. https://academic.oup.com/book/36527